@SpringBootApplication
public class CoffeeApplication {
public static void main(String[] args) {
SpringApplication.run(CoffeeApplication.class, args);
}
}
[코드 1-1]과 같이 Spring Boot Application 클래스에 @SpringBootApplication 애너테이션을 추가하면 기본적으로 해당 애플리케이션이 Spring Boot 기반의 애플리케이션으로 동작하도록 해줍니다.
그렇다면 @SpringBootApplication 은 내부적으로 어떤 기능을 하는 걸까요?
@SpringBootApplication은 다음과 같은 세 가지 기능을 활성화 하는데 사용됩니다.
@EnableAutoConfiguration
Spring Boot의 자동 구성 메카니즘을 활성화합니다.
@ComponentScan
애플리케이션 내의 패키지에서 @Component 애너테이션이 붙은 클래스들에 대한 스캐닝을 활성화합니다.
@SpringBootConfiguration
Spring Context에 Bean을 추가적으로 등록하거나 Configuration 클래스를 추가적으로 임포트 하는 기능을 활성화합니다.
Spring Boot의 @*Test 애너테이션을 사용해서 테스트를 진행할 경우, 자동으로 @SpringBootConfiguration을 검색합니다.
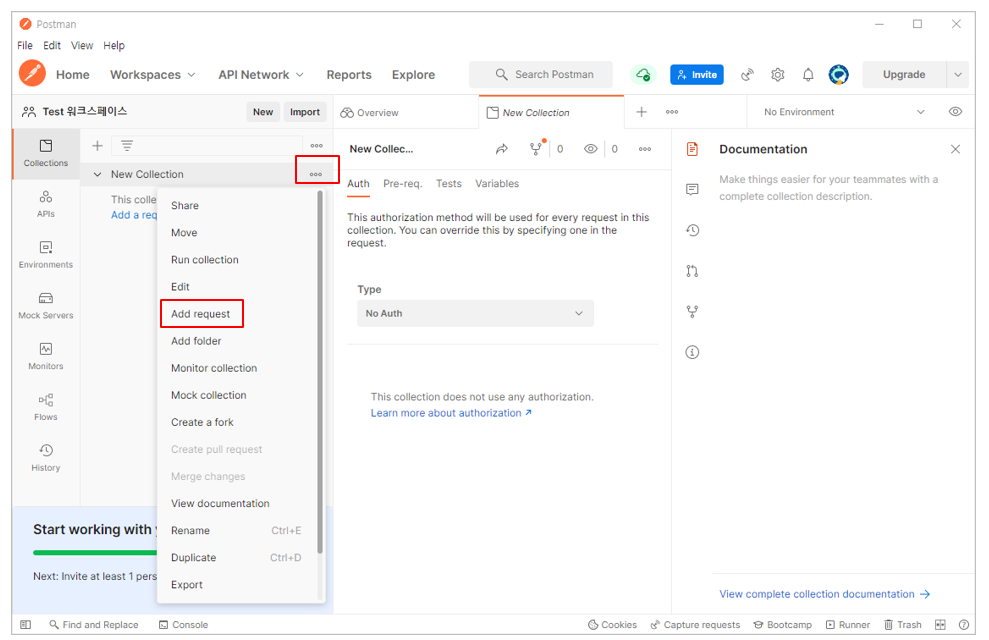
@SpringBootApplication을 무조건 붙여야 하는것은 아니며, [코드 1-2]와 @SpringBootApplication 이 지원하는 세 가지 기능을 개별적으로 적용할 수 있습니다.
[코드 1-2]
@SpringBootConfiguration(proxyBeanMethods = false)
@EnableAutoConfiguration
@Import({ CoffeeConfiguration.class, MemberConfiguration.class })
public class CoffeeApplication {
public static void main(String[] args) {
SpringApplication.run(CoffeeApplication.class, args);
}
}
REST(Representational State Transfer)는 HTTP 네트워크 상의 리소스(Resource, 자원)를 정의하고 해당 리소스를 URI라는 고유한 주소로 접근하는 접근 방식을 의미하며, REST API란 REST 방식을 통해서 리소스에 접근하기 위한 서비스 API를 지칭합니다.
REST에서 의미하는 리소스란?
REST에서 의미하는 자원은 데이터베이스에 저장된 데이터, 문서, 이미지, 동영상 등 HTTP 통신을 통해 주고 받을 수 있는 모든 것을 의미합니다.
URI는 네트워크 상에 있는 특정 리소스를 식별하는 통합 자원 식별자(Uniform Resource Identifier)를 의미합니다.
URL은 인터넷에 있는 리소스를 나타내는 통합 리소스 식별자를 의미하며, 우리가 흔히들 이야기하는 웹 상의 주소를 의미합니다.
URI는 URL의 상위 개념으로 볼 수 있습니다.
URI는 리소스를 식별하는 식별자 역할을 하고, URL은 리소스의 위치를 가리킵니다.
예) http://www.itivllage.tistory.com/manage? id = 1
위 예에서 'http://www.itivllage.tistory.com/manage'까지는 리소스의 위치를 가리키는 URL이라고 할 수 있고, 'http://www.itivllage.tistory.com/manage? id = 1'는 리소스를 식별하기 위한 'id = 1'이라는 고유 식별자 붙었으므로 URI라고 할 수 있습니다.
REST API URI 작성 규칙
그러면 이번에는 HTTP 상에서 REST API 서비스를 만드는 입장에서 REST API URI를 작성하는 규칙들을 살펴보도록 하겠습니다.
핸들(Handle) 이라고 하면 일반적으로 자동차의 핸들을 제일 먼저 떠올릴 수 있는데, 자동차의 핸들은 운전자가 직접 핸들을 움직이면서 직접적으로 자동차의 주행을 처리하는 역할을 합니다.
Spring MVC에서는 자동차의 핸들과 마찬가지로 클라이언트의 요청을 처리하는 처리자를 Handler라고 합니다.
그렇다면 Spring MVC에서 Handler는 누구일까요? Spring MVC에서의 요청 Handler는 바로 여러분들이 작성하는 Controller 클래스를 의미합니다. 그리고 Controller 클래스에 있는 ‘@GetMapping, @PostMapping’ 같은 애너테이션이 붙어 있는 메서드들을 핸들러 메서드라고 합니다.
HandlerMapping이란 의미는 결국 사용자의 요청과 이 요청을 처리하는 Handler를 매핑해주는 역할을 하는 것입니다.
그렇다면, 사용자의 요청과 Handler 메서드의 매핑은 어떤 기준으로 이루어질까요? @GetMapping(”/coffee”) 처럼 HTTP Request Method(GET, POST 등)와 Mapping URL을 기준으로 해당 Handler와 매핑이 되는데 Spring 에서는 여러가지 유형의 HandlerMapping 클래스를 제공하고 있습니다.
실무에서는 Spring에서 디폴트로 지정한 ‘RequestMappingHandlerMapping’을 대부분 사용하는데 원한다면 얼마든지 HandlerMapping 전략을 바꿀 수 있습니다.
Adapter의 의미
Java에서 사용하는 클래스나 인터페이스의 이름을 살펴보다 보면 흥미로운 용어들이 많이 나옵니다. Adapter라는 용어도 그 중에 하나라고 볼 수 있습니다.
우리말로 아답터, 어댑터(Adapter, Adaptor)하면 220V 전압을 110V 전압으로 또는 그 반대로 바꿔주는 어댑터(일명, 돼지코)나 USB 충전기를 떠올릴 수 있습니다.
220V를 5V 전압으로 바꿔주는 USB 충전기 예
이처럼 Adapter는 무언가를 다른 형식이나 형태로 바꿔주는 역할을 합니다.
그렇다면 HandlerAdater는 무엇을 바꿔줄까요?
Spring은 객체지향의 설계 원칙을 잘 따르는 아주 유연한 구조를 가지는 프레임워크입니다. 따라서 Spring이 제공하는 Spring MVC에서 지원하는 Handler를 사용해도 되지만 다른 프레임워크의 Handler를 Spring MVC에 통합할 수 있습니다.
이처럼 다른 프레임워크의 핸들러를 Spring MVC에 통합하기 위해서 HandlerAdapter를 사용할 수 있습니다.
ViewResolver의 의미
’Resolve’는 무언가를 해석하고, 해결해주다라는 뜻이 있습니다.
ViewResolver는 DispatcherServlet에서 ‘이런 이름을 가진 View를 줘’ 라고 요청하면 DispatcherServlet에서 전달한 View 이름을 해석한 뒤 적절한 View 객체를 리턴해주는 역할을 합니다.
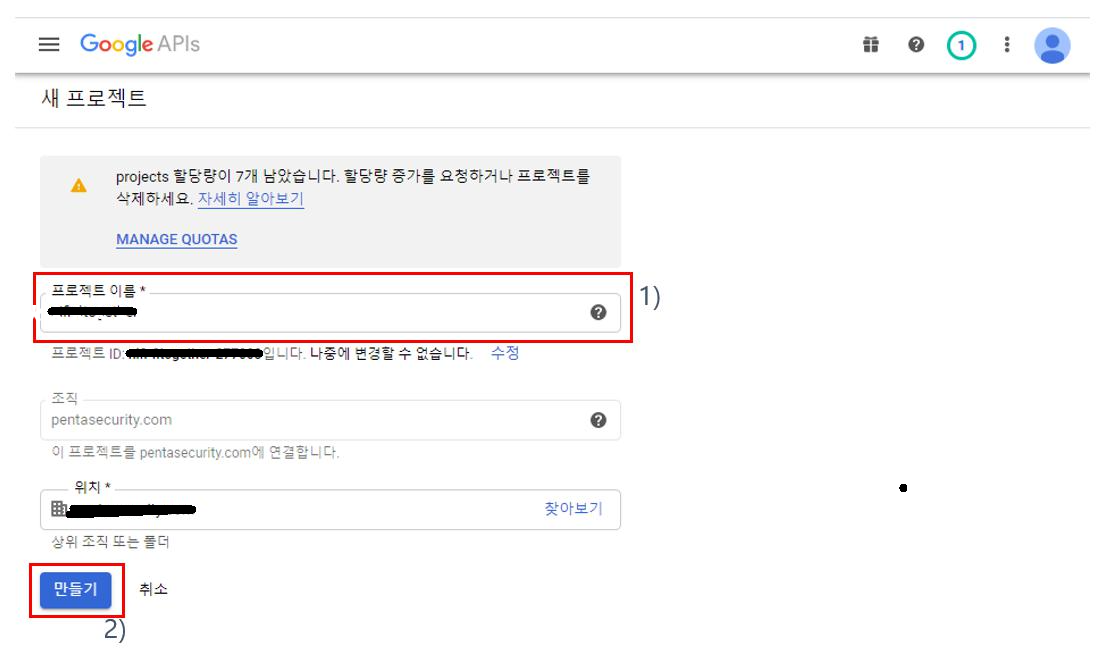
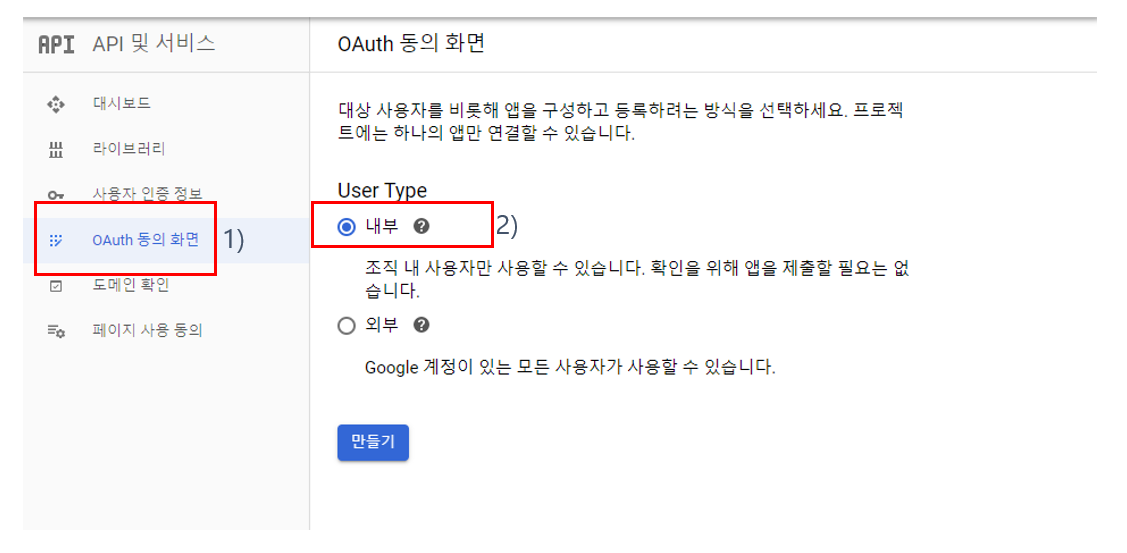
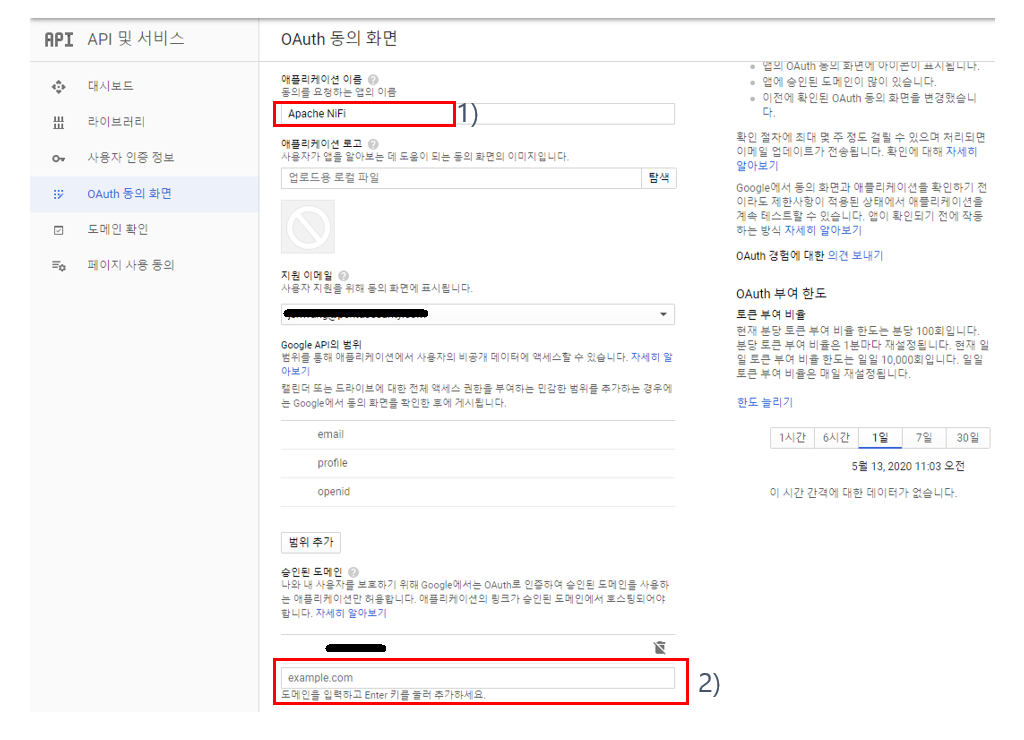
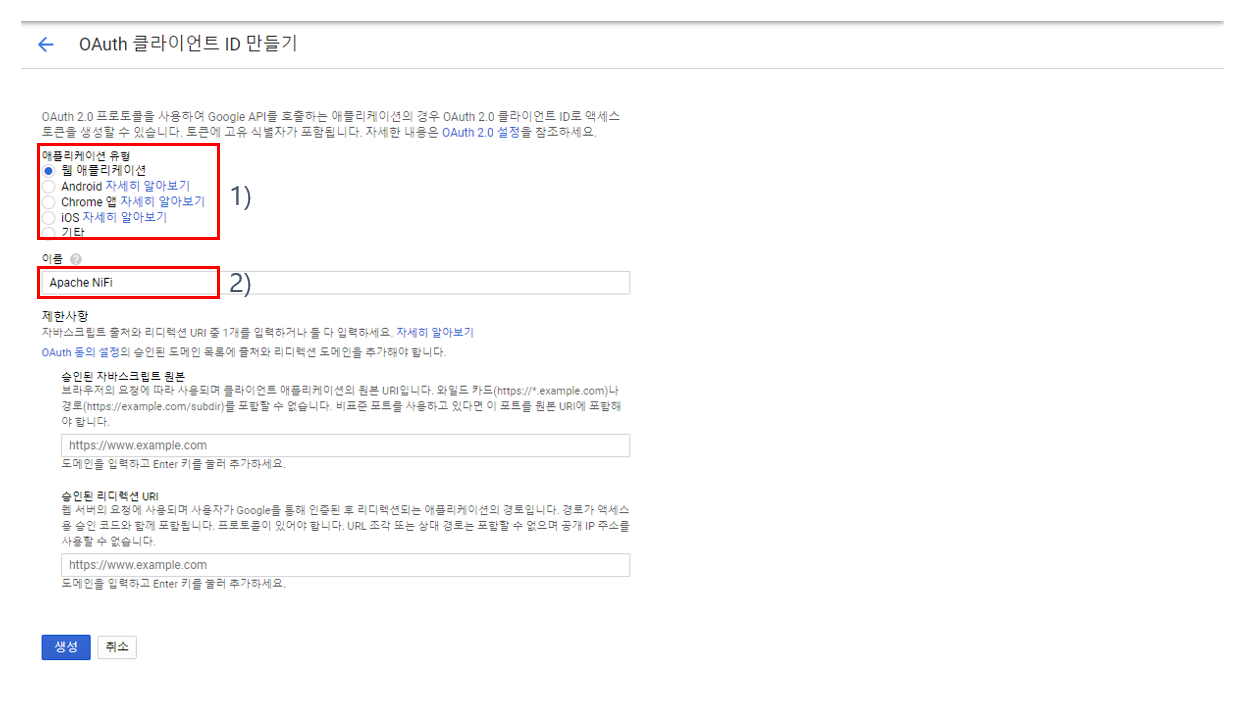
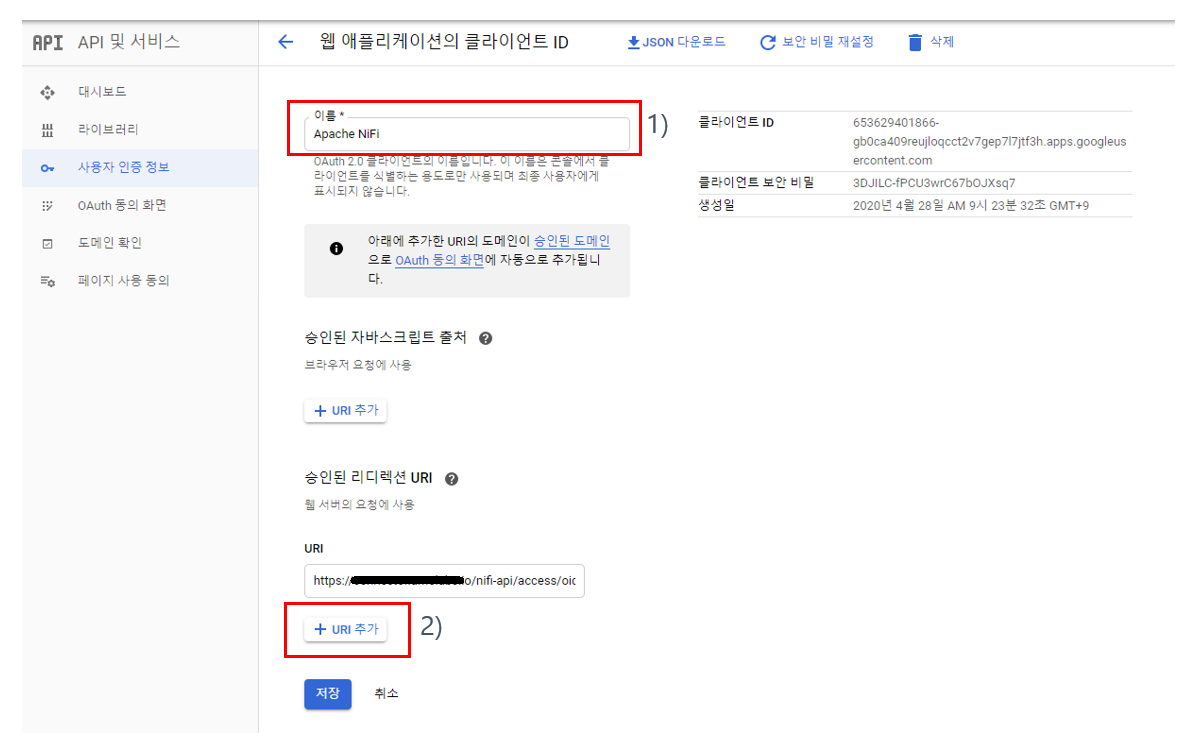
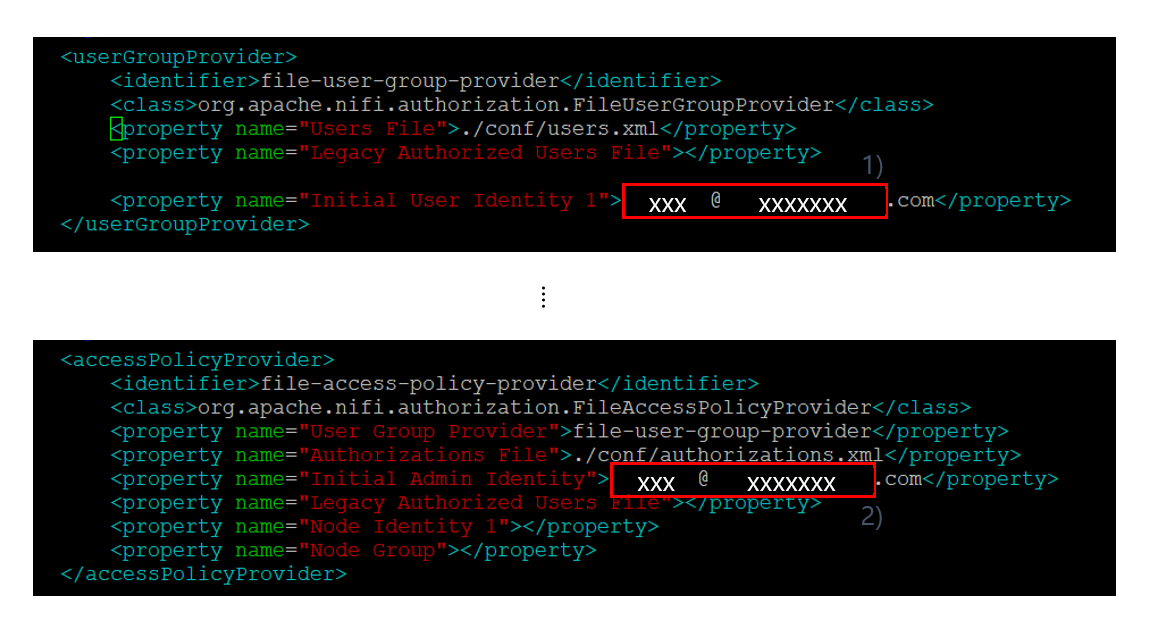
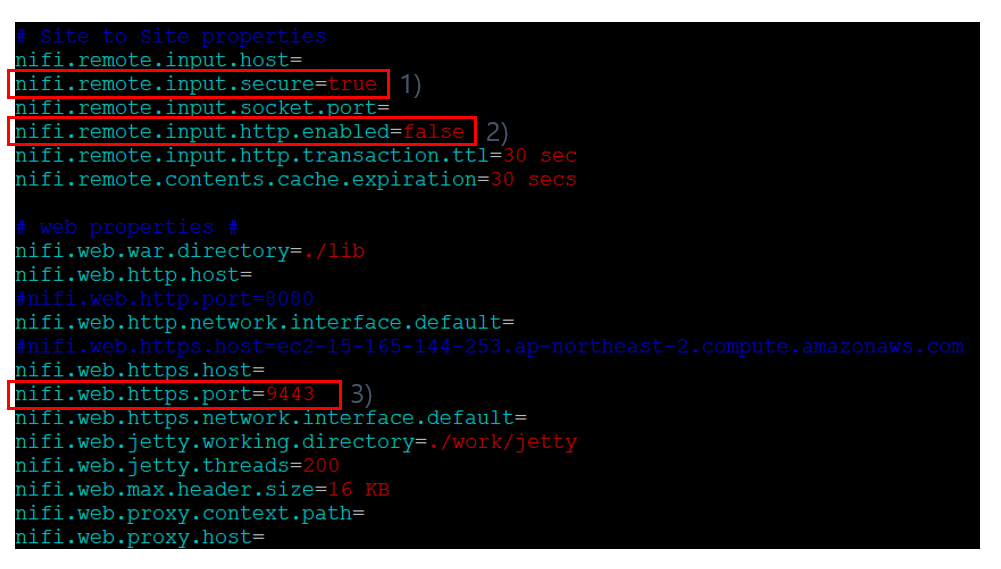
(4) nifi.properties 설정 : Google 클라이언트 ID를 이용한 OpenID Connect 방식의 로그인을 위해 nifi.properties(파일 위치: /home/ubuntu/app/nifi-1.11.4/conf)에 아래와 같이 설정을 추가한다.
(그림 6. nifi.properties에 OpenID Connect 설정)
1) OpenID Connect Provider 검색 URL을 "nifi.security.user.oidc.discovery.url" 프로퍼티의 값으로 입력한다.
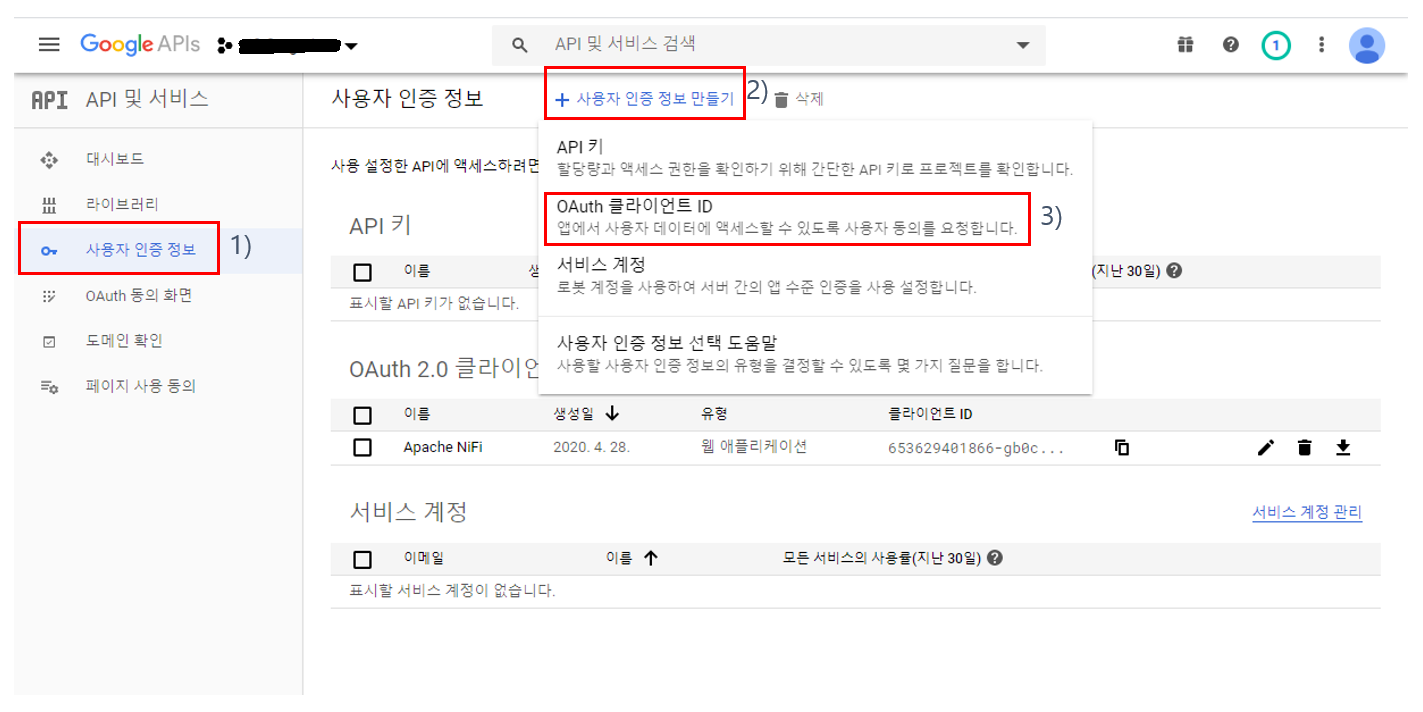
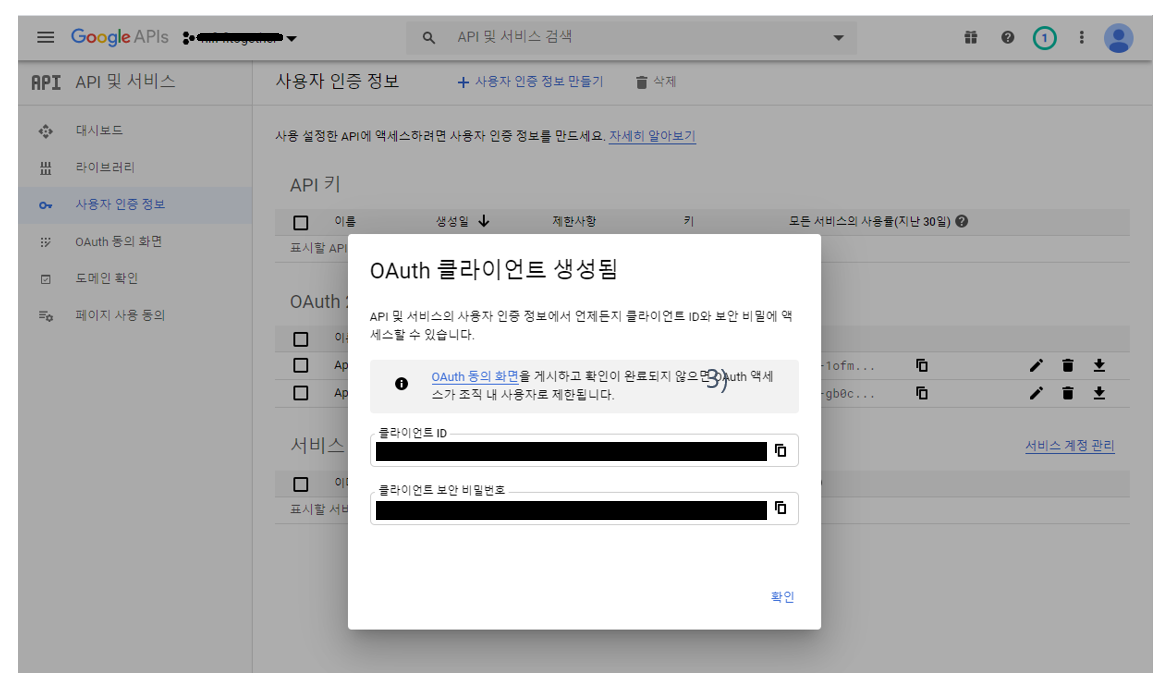
2) (그림 5.3. OAuth 클라이언트 생성 후 팝업)에서 copy하여 보관한 클라이언트 ID를 "nifi.security.user.oidc.client.id" 프로퍼티의 값으로 입력한다.
3) (그림 5.3. OAuth 클라이언트 생성 후 팝업)에서 copy하여 보관한 클라이언트 보안 비밀번호를 "nifi.security.user.oidc.client.secret" 프로퍼티의 값으로 입력한다.
(5) authorizers.xml 파일 설정 : OpenID Connect 로그인을 위한 접근 권한을 부여하기 위해 authorizers.xml(/home/ubuntu/app/nifi-1.11.4/conf) 파일을 아래와 같이 수정한다.
(그림 7. authorizers.xml에 접근 권한 설정)
: 1), 2)에 Google OAuth 클라이언트 ID를 생성할 때 로그인한 Google 이메일 계정을 입력한 후, 파일을 저장한다.
(6) 로그인 테스트
a. NiFi 서버를 stop and start 시킨다.(/home/ubuntu/app/nifi-1.11.4/bin/nifi.sh stop, /home/ubuntu/app/nifi-1.11.4/bin/nifi.sh start)
b. NiFi 서버(https://xxx.xxxxx.com/nifi)로 다시 접속을 한다.
c. 아래와 같이 로그인을 위해 구글 계정을 선택 또는 입력하는 화면에서 authorizers.xml에 등록한 구글 계정을 선택 또는 입력한다.
(그림 8. 구글 계정 선택 또는 입력)
d. 아래와 같이 입력한 구글 계정의 비밀번호를 입력한다.
(그림 9. 구글 계정의 비밀번호)
e. 아래와 같이 NiFi 캔버스가 오픈되고, 좌측 상단에 구글 이메일 계정이 보이면 정상적으로 로그인이 된것이다.
(그림 10. OpenID Connect 방식으로 로그인 한 화면)
: 로그인에 성공하면 1)과 같이 구글 계정이 표시된다. 로그 아웃을 하기 위해서는 1)에서 "LOG OUT" 링크를 클릭하면 정상적으로 로그 아웃된다. "LOG OUT" 링크를 클릭했을때 자동으로 다시 로그인이 된다면 구글 사이트로 이동해서 구글 계정 자체를 로그아웃한 다음에 다시 한번 시도한다.
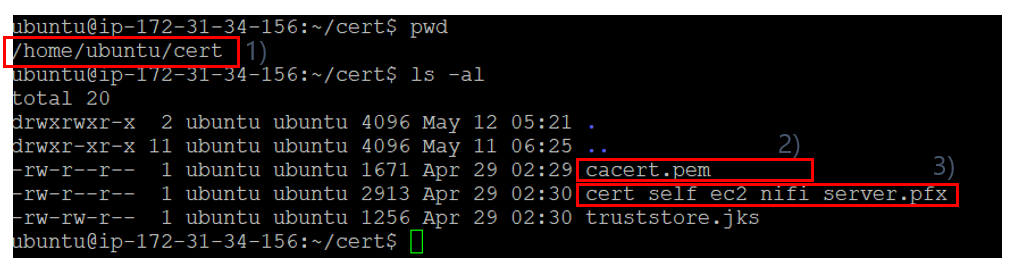
: NiFi 서버에 로그인 화면을 적용하기 위해서는 SSL 연동이 필수이다. 현재(2020년 5월 12일 기준) EC2에 생성된 NiFi 서버의 SSL 인증서는 Self Signed Certificate을 사용하였으며, OpenSSL 툴을 사용하지 않고 좀 더 빠르게 Self Signed Certificate을 생성하기 위해 TinyCert(https://www.tinycert.org/)를 이용하였다.
(1) 인증서 생성 : NiFi 서버에 SSL 설정을 하기 위해서는 먼저 TinyCert 에서 CA 인증서와 서버 인증서를 생성 및 다운로드해야하는데 절차는 다음과 같다.
a. TinyCert에 접속하여 먼저 Sing Up을 한다. Email Address와 Password, Passphrase를 입력 해야 하는데 Passphrase는 서버 인증서를 NiFi 서버에 구성할때 필요하므로 기억을 해야한다.
b. TinyCert에 로그인이 된 상태에서 아래 (그림 1. CA 생성)에서와 같이 메인 화면에서 CA 인증서를 생성한다.
(그림 1. CA 생성)
1) "Create" 버튼을 클릭하여 CA 인증서를 생성한다. CA 인증서 항목은 적절하게 입력해주면 된다.
c. 서버 인증서 생성
(그림2. 서버 인증서 생성)
1) "Create" 버튼을 클릭해서 서버 인증서를 생성한다. 서버 인증서 항목은 적절하게 입력해주면 된다.
d. CA 다운로드
(그림3. CA 다운로드)
1) "다운로드" 버튼을 클릭해서 CA 인증서를 다운로드한다.
e. 서버 인증서 다운로드
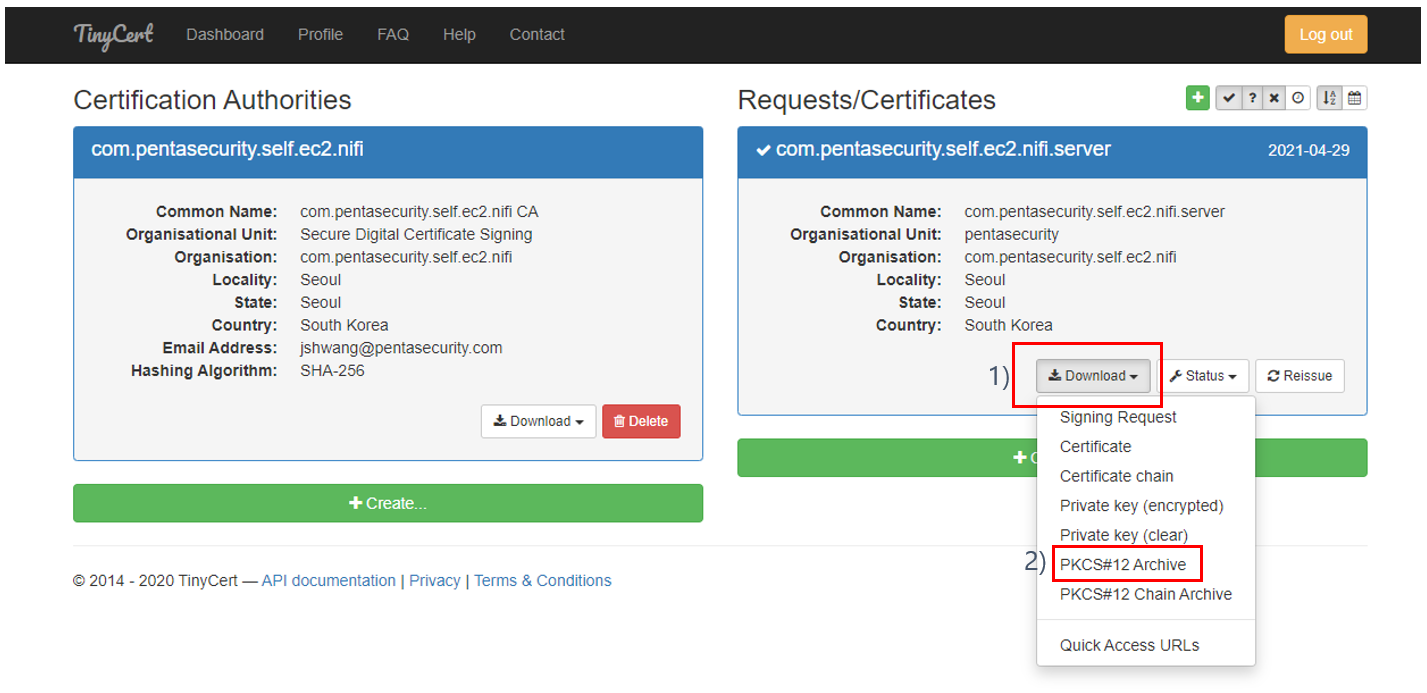
(그림 4.1. 생성된 서버 인증서 목록)
1) 생성된 서버 인증서 목록을 클릭한다.
(그림 4.2. 생성된 서버 인증서 상세)
1) "다운로드" 버튼을 클릭해서 서버 인증서를 다운로드 버튼을 클릭한다.
2) 서버 인증서 타입을 "PKCS#12 Archive" 타입으로 선택하면 서버 인증서가 다운로드 된다.
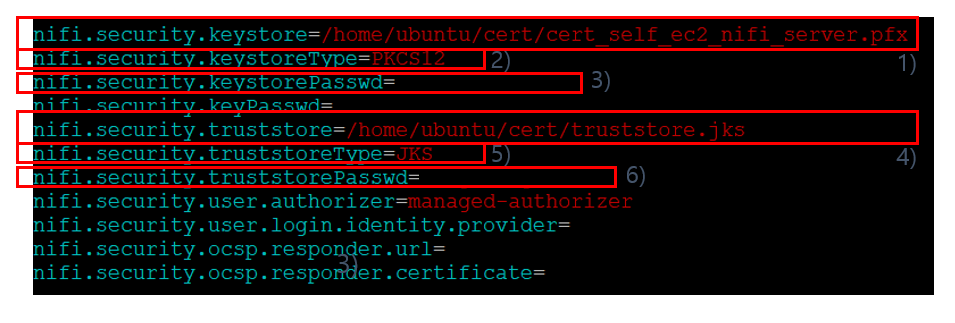
(2) NiFi 서버에 인증서 업로드 : 로컬 PC에 다운로드 받은 CA 인증서와 서버 인증서를 AWS EC2에 설치된 NiFi 서버쪽으로 업로드를 해야하는데 이를 위해서는 EC2 인스턴스에 해당하는 Private Key가 필요하다. Private Key는 개발 담당자(2020년 5월 12일 기준: 황정식)에게 문의한다. 아래 링크의 문서를 참조해서 다운로드 받은 CA 인증서와 서버 인증서를 NiFi 서버쪽으로 업로드한다.
6) "nifi.security.truststorePasswd" 프로퍼티의 값으로 Truststore를 생성할 때 설정한 패스워드를 입력한다.
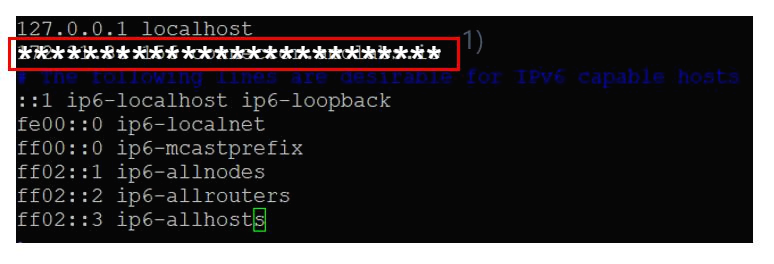
(5) hosts 파일 설정 : NiFi 서버에 접속하는 사용자는 (6)에서 설명할 도메인을 통해서 NiFi 서버에 접속을 할 수 있는데, 이 도메인은 EC2에서 추가한 외부 IP인 탄력적 IP와 매핑이 되어 있다. 하지만 NiFi 서버 입장에서는 EC2 인스턴스 내부 IP와 매핑이 되어야하므로 hosts 파일에 매핑 정보를 추가해주어야 한다.
a. hosts 파일의 경로 : /etc/hosts
b. 내부 IP는 "hostname -I" 명령어로 확인 가능하며, NiFi 서버가 설치된 EC2 인스턴스의 내부 IP는 "172.31.34.156" 이다.
b. (그림 8. 도메인과 내부 IP 매핑 정보)와 같이 매핑 정보를 추가해준다.
1) EC2 인스턴스의 내부 IP와 도메인 매핑 정보를 hosts 파일에 추가한다.
(6) 접속 테스트
a. nifi.sh 명령을 사용해 NiFi 서버를 가동 시킨다. nifi.sh 전체 명령어는 아래와 같다.
이번 시간에는 'Hello, Reactor' 코드를 가지고 Reactor의 기본 구조를 들여다보는 시간을 가져보겠습니다.
개발에 처음 입문하실때 대부분 'Hello World!' 코드를 실행해보셨을텐데요. Reactor 역시 마찬가지로 'Hello, Reactor' 메시지를 출력해보면서 Reactor의 기본 구조를 간단하게 살펴보도록 하겠습니다.
어렵지 않으니 가벼운 마음으로 글을 읽어주시면 감사드리겠습니다.^^
먼저 아래의 코드를 보시죠.
[Hello Reactor 코드]
여러분들이 아시다 시피 Reactor는 RxJava와 마찬가지로 Reactive Streams라는 표준 사양을 구현한 구현체입니다. 따라서 Reactive Streams에서 정의하고 있는 생산자 즉, Publisher와 소비자 즉, Subscriber를 구현하고 있는데요.
위의 코드에서 보시는것처럼 Reactor에서는 Flux가 대표적인 생산자 중에 하나입니다. 위의 코드에서 소비자라고 되어 있는 부분은 람다 베이스 Subscriber가 되겠습니다.
생산자 쪽에서는 just라는 Operator(연산자)를 사용해서 두 개의 데이터를 소비자 쪽으로 통지를 하는데요. Reactor에서는 생산자 쪽에서 통지할 데이터를 정의하는 과정 자체를 묶어서 'Sequence(시퀀스)'라고 합니다. 이 Sequence라는 용어는 Reactor를 접하다보면 자주 나오는 용어이니 기억을 해두시길 바래볼게요.
생산자 쪽에서 소비자 쪽으로 데이터를 통지하는것이 맞긴하지만 최종 소비자까지 데이터가 전달 되기까지는 중간에 여러 Operator를 만날 수 있기때문에 엄밀히 말하자면 생산자가 소비자에게 데이터를 통지한다라고 말하기보다는 생산자가 Downstream으로 데이터를 내보낸다라는 표현이 더 정확할 것 같네요.
용어에 대한 부분은 아래쪽에서 다시 정의를 해보도록 하구요.
아무튼 생산자 쪽에서 데이터를 통지하게 되면 최종 소비자 쪽에 바로 데이터가 전달되는 것이 아니라 map( )이라는 Operator에서 원본 데이터가 가공 처리 된 후에 최종 소비자 쪽으로 전달이 되는것을 볼 수 있는데요.
여기서는 통지된 String 데이터를 소문자로 변환을 한 후에 최종 소비자쪽으로 전달하고 있네요.
자, RxJava 강의 시간에도 말씀을 드렸지만 리액티브 프로그래밍은 크게 세가지의 step으로 이루어져있습니다.
1 step : 생산자가 데이터를 통지한다. 2 step : 통지된 데이터를 Operator로 가공한다. 3 step : 가공 처리된 데이터를 최종 소비자에게 전달한다.
이 세가지 큰 흐름은 기본적으로 꼭 기억을 해두시고, 나머지는 데이터를 통지하는 다양한 방법, 데이터를 가공하는 다양한 방법, 비동기 프로그래밍을 위한 쓰레드를 할당하는 방법, 에러 처리 방법 등을 단계적으로 적용 하는 식으로 학습을 진행해 나가면 리액티브 프로그래밍을 조금 더 수월하게 이해하실 수 있을거라는 생각이 드네요. ^^;
자, 그럼 마지막으로 Reactor에 대한 에피소드를 계속 진행가기 전에 Reactor에서 사용되는 여러가지 용어를 정의하고 에피소드를 마무리 하도록 하겠습니다.
먼저 아래 용어들을 보시죠.
Publisher : 발행자, 게시자, 생산자, 방출자(Emitter)
Subscriber : 구독자, 소비자
Emit : Publisher가 데이터를 내보내는 것(방출하다. 내보내다. 통지하다.)
Sequence : Publisher가 emit하는 데이터의 연속적인 흐름. 스트림과 같은 의미라고 보면 됨
Subscribe : Subscriber가 Sequence를 구독하는 것
Dispose : Suscriber가 Sequence 구독을 해지 하는 것
Downstream : 현재 Operator 체인의 위치에서 봤을때 데이터가 전달 되는 하위 Operator 및 method 체인
Upstream : 현재 Operator 체인의 위치에서 봤을때 상위 Operator 및 method 체인
여태껏 제가 데이터를 통지하는 쪽은 생산자로 지칭했는데요. 보시는대로 생산자 이외에 발행자, 게시자, 방출자 등 다양하게 사용이 되고 있습니다. 모두 같은 의미라고 보시면 되겠지만 앞으로 에피소드를 진행할 때는 그냥 영어로 Publisher라고 지칭하도록 하겠습니다. ^^;
따라서 소비자 역시 영어로 Subscriber라고 지칭하면 되겠구요.
데이터를 통지하는 행위 역시 영어 그대로 Emit 한다라고 하겠습니다.
Sequence는 위에서 잠깐 말씀 드렸죠? Publisher쪽에서 데이터를 emit하는 흐름 자체를 통칭하는 것을 의미하는데, 예를 들어서 Flux라는 Publisher가 데이터의 Emit을 정의하는 부분을 설명할때 Sequence를 생성한다 라고 표현할 수 있겠습니다.
Subscribe와 Dispose는 구독하다, 구독을 해지하다라고 표현하도록 하겠습니다.
마지막으로 Downstream과 Upstream이라는 용어인데요. Reactor를 학습하다보면 종종 나오는 용어인데 개념적으로 이해하기 모호한 면이 있는 용어중에 하나이기도 합니다.
이럴때는 그냥 단순하게 이해를 하는게 제일 좋을거라고 생각을 해보게되네요. ^^; 예를 들어 위의 코드에서 just( )의 위치에서 Downstream은 map( )부터 subscribe( )까지 하위 체인이 되겠습니다. 그리고 subscribe( ) 입장에서는 map( )과 just( )가 Upstream이 되겠구요.
just( )의 내부를 들여다보면 return 값으로 Flux를 반환하는데요. just( )에서 반환하는 Flux를 원본 Flux가 되겠습니다. 그리고 map( )에서 반환하는 return 값 역시 Flux인데요. 여기서의 Flux는 원본 Flux가 아닌 가공 처리된 데이터를 가지고 있는 새로운 Flux입니다.
Flux(또는 Mono)의 이러한 처리 흐름때문에 Downstream이나 Upstream이라는 용어가 생겨난것 같은데 위에서 언급드린것처럼 단순하게 생각해주시면 될것 같아요.
자, 오늘은 'Hello, Reactor' 코드를 통해서 Reactor 의 기본 구조를 살펴보았는데요. 다음 시간에 다른 에피소드를 가지고 다시 찾아뵙도록 하겠습니다. ^^
수강생 여러분 안녕하세요. RxJava 강의를 진행하고있는 Kevin입니다. 오늘은 리액티브 프로그래밍과 밀접한 관련이 있는이벤트 루프에대해서 잠시 알아보도록하겠습니다.
이벤트 루프에 대해서 먼저 이야기 하기 전에 저희는 서블릿에 대한 언급을 먼저 하고 넘어가야되는데, 그 이유는 이벤트 루프라는 개념이 나오게 된 배경에는 서블릿이 있기때문이에요.
그럼 서블릿에 대한 이야기를 먼저 해볼까요?
서블릿의 기본 개념
서블릿은 뭘까요? 자바를 사용하는 개발자이거나 자바를 배우고 계신 분들이 웹 애플리케이션을 만들어 보셨다면 이미 서블릿을 사용해보셨을겁니다. 여러분들이 JSP를 사용해보셨거나 아니면 Spring framework을 사용해보셨다면 여러분들은 알게 모르게 서블릿이란 놈을 사용해보셨다는 말씀. ^^
서블릿은 웹에서 클라이언트의 요청을 동적으로 처리하기 위해 서블릿 규약이라는 일정한 규칙에 맞춰서 작성되는 클래스인데요. 이 클래스들이 클라이언트로 부터 들어오는 요청을 받아서 응답으로 되돌려주는 역할을 하죠.
개발자가 작성한 서블릿 클래스가 HttpServlet을 상속 받고, doGet( ), doPost()를 구현하는 것이 서블릿 클래스의 기본이라는 사실은 서블릿 클래스를 사용해보신분들은 너무나 잘 알고들 계실겁니다.
Spring에서의 서블릿
어쨌든 저희가 HttpServlet 같은 상위 클래스를 상속 받아서 개발을 진행할건 아니기때문에 서블릿에 대해서 더 자세한 이야기를 할 필요는 없을 것을 같네요. 다만, 이것 하나만은 기억을 하셔야 될 것 같습니다. Spring MVC 역시 내부적으로는 Servlet 기술을 사용을 한다는것을요. DispatcherServlet 이라는 녀석을 기억하시죠? Spring MVC에서는 이 DispatchServlet이라는 녀석이 최앞단에서 클라이언트의 요청을 전달 받아서 해당 요청에 매핑되는 Controller 에게 요청을 전달한다는 사실은 Spring MVC로 개발을 해보신분들은 잘 알고 계실겁니다.
서블릿 방식의 문제점
그런데 이러한 서블릿을 사용하여 클라이언트의 요청을 처리하는 방식에는 큰 문제점이 하나 있는데요. 서블릿 방식은 클라이언트에서 요청이 들어오면 해당 요청을 처리하기 위해서 요청 당 쓰레드 하나씩을 생성해서 처리합니다. 하나의 쓰레드에서 클라이언트의 요청을 다 처리하면 이 쓰레드는 쓰레드풀이라는 쓰레드의 저장소에 다시 반납이 되는데, 참고로 이 쓰레드 풀은 톰캣 같은 서블릿 컨테이너가 관리를 해줍니다. 사실 클라이언트의 요청이 폭주만 하지 않으면 지금과 같은 서블릿 방식이 큰 문제가 되지는 않겠지만 클라이언트의 요청이 쓰레드의 갯수에 비해 기하급수적으로 늘어나는 순간 문제가 시작됩니다. 요청을 처리하기 위한 쓰레드가 쓰레드 풀에 남아있지 않을 경우 기존에 사용되던 쓰레드가 쓰레드 풀에 다시 반납이 되어 다른 요청을 처리하기 위해서 재사용할 수 있 때까지 클라이언트로 부터 들어온 요청들은 대기를 해야되니까요. 이런 성능상의 문제점을 상당 부분 해소할 수 있는 방식이 바로 이벤트 루프 방식인데요. 그럼 이벤트 루프 방식이 무엇인지, 어떻게 클라이언트의 요청을 효과적으로 처리하는지 간단하게 살펴볼까요?
이벤트 루프란
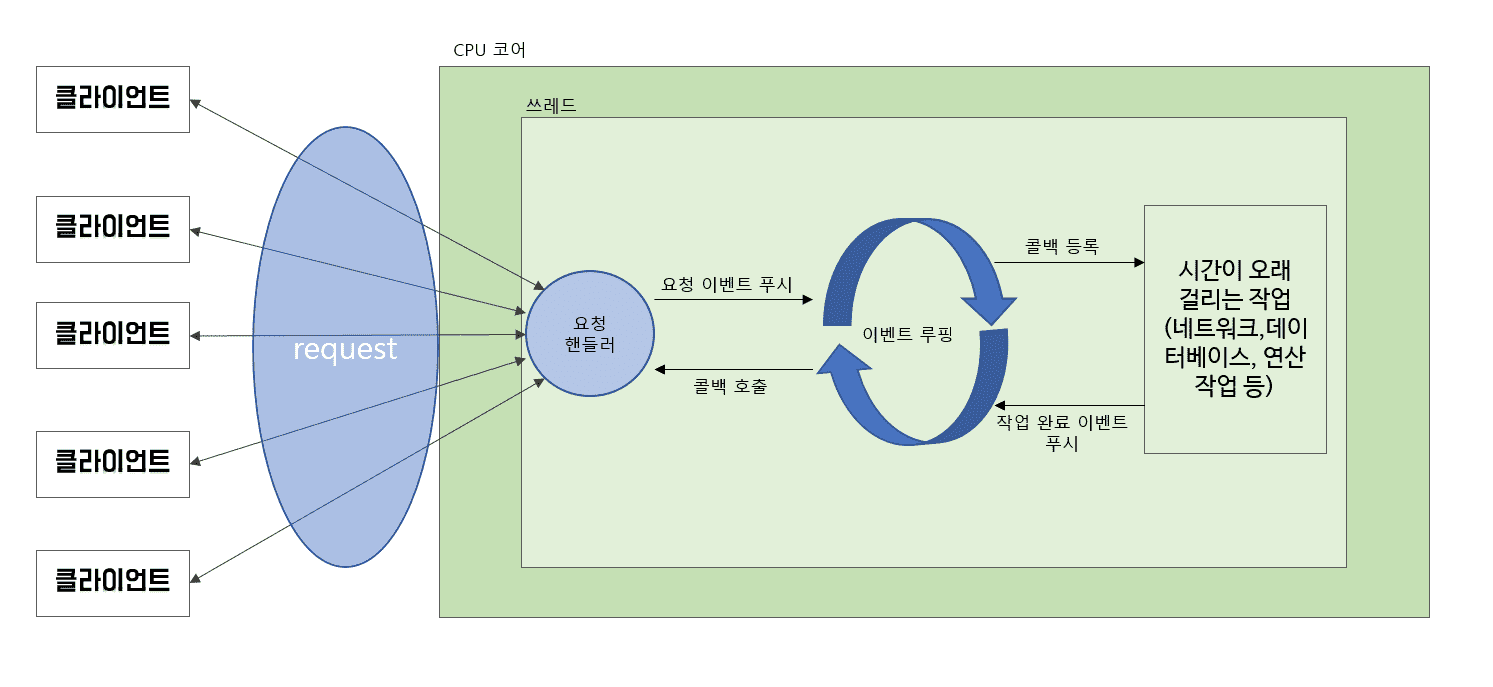
아래 그림을 보면서 이벤트 루프에 대해서 설명 드리겠습니다.
클라이언트가 서버로 요청을 보내면 요청 핸들러가 클라이언트의 요청이 들어왔다는 이벤트를 이벤트 루프에 푸시합니다.
이벤트 루프는 그림과 같이 계속해서 루프를 돌면서(한마디로 무한루프) 요청 핸들러로부터 푸시된 이벤트를 감지합니다. 그리고 나서 해당 이벤트에 대한 콜백을 등록한 후, 클라이언트가 요청한 작업을 처리합니다. 작업이 끝나면 작업이 끝났다는 이벤트를 이벤트 루프에 푸시하고 등록된 콜백을 호출한 후, 요청 핸들러를 다시 거쳐서 클라이언트에게 최종적으로 응답을 되돌려줍니다. 어떠신가요? 이벤트 루프가 무엇인지 대충 감이 오시는지 모르겠네요.
이벤트 루프 방식의 장점은 쓰레드 하나로 굉장히 많은 요청을 병렬로 처리하기때문에 기존의 서블릿 방식의 성능상의 문제를 해결한다는것입니다.
WebFlux와 이벤트 루프
Spring WebFlux가 바로 이벤트 루프 방식을 사용하기때문에 대량의 클라이언트 요청을 효과적으로 처리할 수 가 있게되었는데요. Spring WebFlux를 사용해서 대량의 클라이언트 요청을 효과적으로 처리하는 애플리케이션을 한번 만들어보고 싶어지지 않으셨나요? ^^;
Spring MVC냐 Spring WebFlux냐
자, 그러면 무조건적으로 Spring MVC 대신에 Spring WebFlux를 사용하면 좋은것이냐하면 사실 그건 아닌것같습니다. Spring MVC로 개발을 진행해보셨다면 아시겠지만 생산성이 대단하다는것을 느끼실 수가 있을겁니다. 그리고 RxJava 2부 강의에서 비동기 방식의 디버깅에 대한 이야기를 드리겠지만 비동기 방식보다는 동기 방식이 디버깅도 용이하고 여태껏 사용해온 익숙한 명령형 프로그래밍 방식으로 코드를 짜면 되니 코드를 짜는 부담 역시 줄어드는게 사실일테구요. 하지만 분명한것은 사물 인터넷, 자동차, 인공 지능 등등 우리가 생각하는 전통적인 클라이언트 이외에 다양한 클라이언트들이 계속해서 생겨날텐데 이런 종류의 클라이언트들이 계속해서 생겨나면 생겨날수록 서버가 감당해야 되는 요청의 수는 점점 늘어나겠죠. 마이크로 서비스로 인해서 또한 서비스들 간의 요청도 점점 늘어나고 있기도 하구요.
결론은 지금 당장은 아니더라도 개발자로서 미래를 준비하고 싶으신 분은 리액티브 프로그래밍 기법을 꼭 익혀두셨으면 하는 바램입니다. ^^ 이야기는 길었는데 결론은 꽤 간단하다는.. ^^;;
오늘은 이벤트 루프에 대한 이야기를 간단하게 해보았는데요. Spring WebFlux에 대한 이야기로 또 찾아뵙도록 할게요.